Excel 에서 z-점수 계산 방법: 종합 가이드
통계학 및 데이터 분석 분야에서는 데이터가 평균과 어떻게 비교되는지를 이해하는 것이 매우 중요합니다。 z-점수(또는 표준 점수라고도 함)는 데이터 포인트가 데이터셋 평균으로부터 표준편차 단위로 얼마나 떨어져 있는지를 측정하는 방법을 제공합니다。 시험 점수, 재무 데이터 또는 기타 수치형 데이터셋을 분석하든, z-점수를 계산하면 데이터의 행동에 대한 깊이 있는 통찰을 얻을 수 있습니다。
Excel 을 사용하여 z-점수를 계산하면 간단하고 효율적이며 대규모 데이터셋에 대한 표준화된 비교 및 이상치 탐지를 빠르게 수행할 수 있습니다. 이 자습서에서는 z-점수가 무엇인지 이해하고 Excel 에서 이를 찾는 방법, 수식 예시, 데이터 내 z-점수 해석 방법, 그리고 이러한 계산을 수행할 때 기억해야 할 중요한 팁을 안내해 드립니다。 | 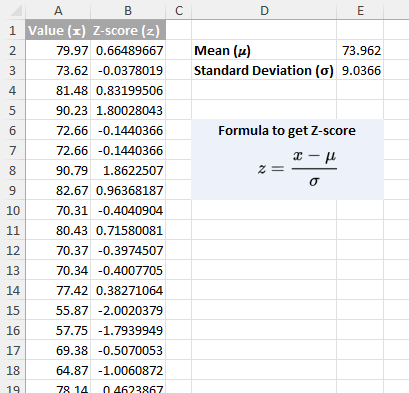 |
z-점수란 무엇인가요?
z-점수(또는 표준 점수라고도 함)는 특정 데이터 포인트가 데이터셋 평균으로부터 표준편차 단위로 얼마나 떨어져 있는지를 정량화하는 통계 지표입니다。 이 측정값은 데이터 포인트가 데이터셋 평균값으로부터 어느 방향(위 또는 아래)으로, 그리고 얼마나 멀리 벗어나 있는지를 이해하는 데 필수적입니다。 본질적으로 z-점수는 데이터 포인트를 공통 척도로 변환하여 원래 측정 척도나 분포 형태와 무관하게 서로 다른 데이터셋 간 또는 다양한 집단 내에서 쉽게 비교할 수 있도록 해줍니다。
z-점수 개념은 정규분포와 밀접하게 연결되어 있습니다。 정규분포는 통계학의 기본 개념으로, 대부분의 관측값이 중심 피크 주변에 집중되고 평균에서 양쪽 방향으로 대칭적으로 값이 나타날 확률이 감소하는 분포를 의미합니다。 정규분포 맥락에서: |
|

- 데이터의 약 68% 가 평균으로부터 한 표준편차(±1 z-점수) 범위 내에 분포되어 있어, 평균으로부터 중간 정도의 편차를 보입니다。
- 관측값의 약 95% 는 두 표준편차(±2 z-점수) 범위 내에 위치하며, 이는 상당하지만 극단적이지 않은 편차를 나타냅니다。
- 데이터의 거의 99.7% 가 세 표준편차(±3 z-점수) 범위 내에 포함되어 있으며, 이는 분포 내 거의 모든 관측값을 포괄하고 극단적인 편차를 강조합니다。
z-점수는 통계 분석에서 핵심적인 도구로, 서로 다른 데이터셋의 개별 관측값을 표준화하여 서로 다른 분포에서 나온 점수를 비교할 수 있게 해줍니다。 데이터를 z-점수로 변환함으로써 특정 관측값이 주어진 분포 내에서 얼마나 특이하거나 일반적인지를 쉽게 판단할 수 있으므로, 이상치 탐지, 가설 검정, 데이터 정규화 등 다양한 응용 분야에서 없어서는 안 될 도구입니다。
Excel 에서 z-점수를 찾는 방법은 무엇인가요?
Excel 에는 z-점수를 직접 계산하는 단일 전용 함수가 없습니다。 이 과정은 먼저 데이터셋의 평균()μ)과 표준편차(σ)를 계산하는 것으로 시작됩니다。 이러한 기본 통계값을 얻은 후, z-점수를 결정하는 두 가지 주요 방법이 있습니다:
- 수동 계산 방법: z-점수 공식을 적용합니다:
=(x-μ)/σ - 여기서:
- x는 검토 중인 데이터 포인트이며,
μ는 데이터셋의 평균이고,
σ는 데이터셋의 표준편차입니다。 - STANDARDIZE 함수 사용하기: 보다 통합된 접근을 위해 Excel 의STANDARDIZE함수를 사용하면 데이터 포인트, 평균, 표준편차를 입력값으로 하여 z-점수를 직접 계산할 수 있습니다:
=STANDARDIZE(x, mean, standard_dev)
Excel 에서 z-점수를 계산하는 수식 예시
A 열 A2 부터 A101 까지 데이터셋이 있다고 가정할 때, 해당 값들에 대한 z-점수를 계산하는 방법은 다음과 같습니다:
- 평균()μ) 계산하기: 데이터셋의 평균()μ)을 구하려면AVERAGE(range)함수를 사용하세요。
=AVERAGE(A2:A101)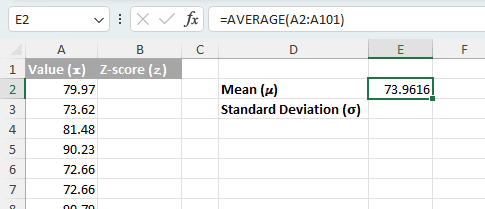
- 표준편차()σ) 계산하기: 데이터 맥락에 따라 적절한 공식을 선택하세요。중요 사항:데이터셋에 맞는 적절한 함수를 선택하는 것은 정확한 계산을 보장하는 데 매우 중요합니다。 (A2:A101 범위의 데이터가 전체 모집단을 나타내므로 저는 첫 번째 공식을 사용하겠습니다。)
- 귀하의 데이터가 전체 모집단을 나타낼 경우(즉, 해당 값들이 더 큰 집단에서 추출되지 않았음을 의미함)STDEV.P(range)함수를 사용하세요。
=STDEV.P(A2:A101) - 귀하의 데이터가 더 큰 모집단의 표본이거나 표본을 기반으로 모집단 표준편차를 추정하려는 경우STDEV.S(range)함수를 사용하세요。
=STDEV.S(A2:A101)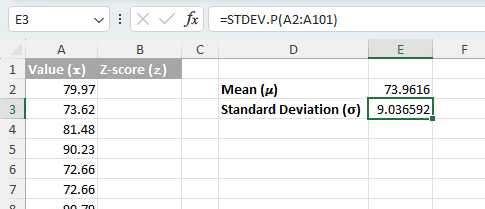
- 귀하의 데이터가 전체 모집단을 나타낼 경우(즉, 해당 값들이 더 큰 집단에서 추출되지 않았음을 의미함)STDEV.P(range)함수를 사용하세요。
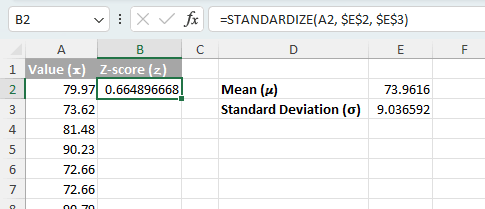
- A2 셀의 데이터 포인트에 대한 z-점수 계산하기: 다음 두 공식 중 하나를 사용할 수 있으며, 동일한 결과를 얻게 됩니다。 (이 경우 두 번째 공식을 사용하겠습니다。)
- 직접 계산데이터 포인트에서 평균을 뺀 후 이 결과를 표준편차로 나누어 수행합니다。
=(A2 - $E$2) / $E$3 - STANDARDIZE(x, mean, standard_dev)함수를 사용하세요。
=STANDARDIZE(A2, $E$2, $E$3)참고:달러 기호()$)는 수식이 복사되는 위치와 관계없이 항상 특정 셀(E2 는 평균, E3 는 표준편차)을 참조하도록 지시합니다。
- 직접 계산데이터 포인트에서 평균을 뺀 후 이 결과를 표준편차로 나누어 수행합니다。
- 데이터셋 내 각 값에 대한 z-점수 계산하기: 3 단계에서 작성한 수식을 열 아래로 복사하여 데이터셋 내 각 값에 대한 z-점수를 계산하세요。팁:셀의 채우기 핸들을 두 번 클릭하면 수식을 빠르게 확장할 수 있습니다。
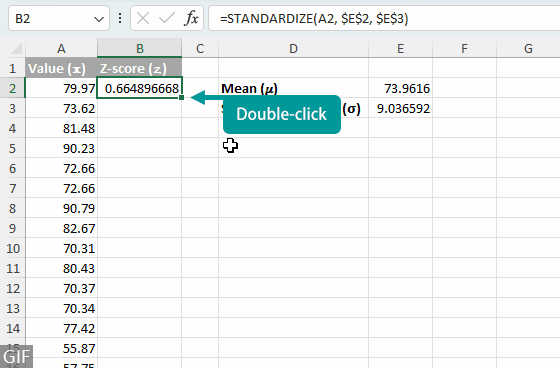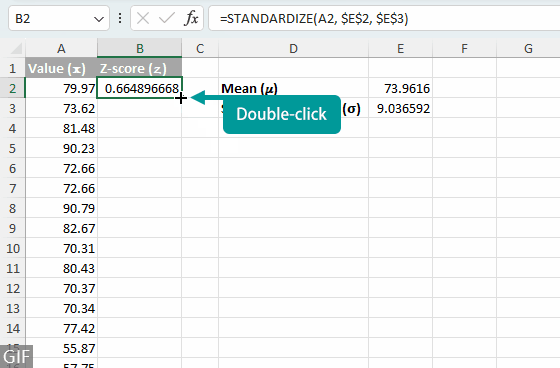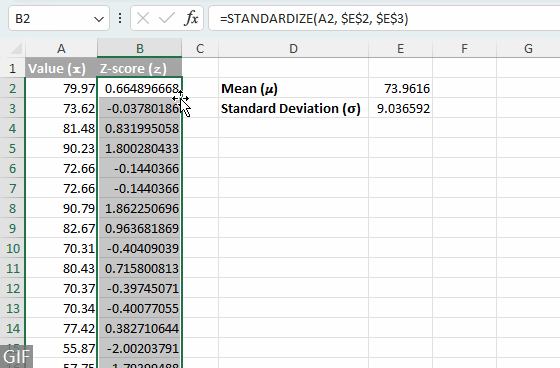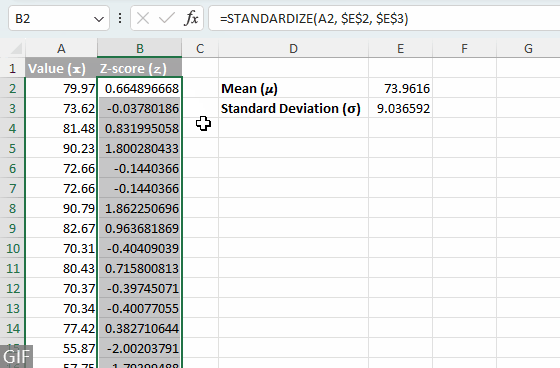




- 평균과 표준편차를 개별 셀에 따로 입력하지 않고 전체 데이터셋에 걸쳐 z-점수 계산을 간소화하려면 다음 중 하나의 포괄적 수식을 직접 사용할 수 있습니다。
=(A2 - AVERAGE($A$2:$A$101)) / STDEV.P($A$2:$A$101)=STANDARDIZE(A2, AVERAGE($A$2:$A$101), STDEV.P($A$2:$A$101)) - 과학 및 통계 작업에서 z-점수를 소수점 셋째 자리까지 일관된 정밀도로 유지하는 것은 매우 바람직한 관행입니다。 z-점수 셀을 선택한 후 홈 탭의 숫자 그룹에서 「소수 자릿수 줄이기」 옵션을 사용하여 이를 구현할 수 있습니다。

데이터에서 z-점수 해석하기
z-점수 해석은 데이터셋 내 데이터 포인트의 위치와 중요성을 이해하는 데 필수적입니다。 z-점수는 요소가 데이터셋 평균으로부터 몇 표준편차 떨어져 있는지를 직접적으로 측정하여 그 상대적 위치와 희귀성을 파악할 수 있는 통찰을 제공합니다。
평균과의 관계
- z-점수 = 0: 데이터 포인트가 정확히 평균에 위치해 있음을 나타내며, 평균적인 성과를 의미합니다。
- z-점수 > 0: 평균보다 높은 값을 나타내며, 평균으로부터 멀어질수록 더 뛰어난 성과를 시사합니다。
- z-점수 < 0: 평균보다 낮은 값을 나타내며, 점수가 낮을수록 평균 이하에서 더 크게 벗어나 있음을 의미합니다。
편차 정도
- |z-점수| < 1: 해당 데이터 포인트는 정규분포에서 데이터의 주요 부분 내에 위치해 있어 평균에 가까우며, 표준적인 성과를 나타냅니다。
- |z-점수| < 2: 평균으로부터 중간 정도의 편차를 나타내며, 관측값이 드물지만 여전히 정상적인 변동 범위 내에 있음을 시사합니다。
- |z-점수| > 2: 평균으로부터 상당히 멀리 떨어진 비정상적인 데이터 포인트를 강조하며, 이상치 또는 기대되는 정상 범위에서 크게 벗어난 값을 나타낼 수 있습니다。
예시 설명:
- 0.66 의 z-점수는 해당 데이터 포인트가 평균보다 0.66 표준편차만큼 높다는 것을 의미합니다。 이는 해당 값이 평균보다 높지만 여전히 상대적으로 가까우며 일반적인 변동 범위 내에 있음을 나타냅니다。
- 반대로, -2.1 의 z-점수는 해당 데이터 포인트가 평균보다 2.1 표준편차만큼 낮다는 것을 의미합니다。 이 값은 평균보다 훨씬 낮아 일반적인 범위에서 상당히 벗어났음을 나타냅니다。
Excel 에서 z-점수를 계산할 때 기억해야 할 사항
Excel 에서 z-점수를 계산할 때는 정밀도와 정확도가 매우 중요합니다。 결과의 신뢰성을 보장하기 위해 반드시 염두에 두어야 할 중요한 사항들이 있습니다:
- 정규분포 여부 확인: z-점수는 정규분포를 따르는 데이터에 가장 효과적입니다。 데이터셋이 정규분포를 따르지 않는 경우, z-점수는 적절한 분석 도구가 아닐 수 있습니다。 z-점수 분석을 적용하기 전에 정규성 검정을 수행하는 것을 고려하세요。
- 올바른 함수 사용 확인: 데이터셋 특성에 따라 전체 모집단에는STDEV.P함수를, 표본에는STDEV.S함수를 사용하여 적절한 표준편차 함수를 선택하세요。
- 평균 및 표준편차에 절대 참조 사용: 여러 셀에 걸쳐 수식을 적용할 때, z-점수 수식 내 평균과 표준편차에 절대 참조(예:$A$1)를 사용하여 계산의 일관성을 유지하세요。
- 이상치 주의: 이상치는 평균과 표준편차 모두에 큰 영향을 미쳐 계산된 z-점수를 왜곡할 수 있습니다。
- 데이터 무결성 확보: z-점수를 계산하기 전에 데이터셋이 오류 없이 깨끗한지 확인하세요。 잘못된 데이터 입력, 중복 또는 관련 없는 값은 평균과 표준편차에 큰 영향을 미쳐 오해를 불러일으킬 수 있는 z-점수를 초래할 수 있습니다。
- 과도한 반올림 또는 절삭 금지: Excel 은 많은 수의 소수 자릿수을 처리할 수 있으며, 이를 보존함으로써 최종 분석을 왜곡할 수 있는 누적 반올림 오류를 방지할 수 있습니다。
위 내용은 Excel 에서 z-점수를 계산하는 것과 관련된 모든 정보를 담고 있습니다。 이 자습서가 도움이 되길 바랍니다。 더 많은 Excel 팁과 트릭을 알아보고 싶으시다면,여기를 클릭하세요수천 개가 넘는 자습서 모음에 접속하실 수 있습니다。
최고의 오피스 생산성 도구
Kutools for Excel - 남들과 차별화되도록 도와드립니다
| 🤖 | KUTOOLS AI 도우미: 다음을 기반으로 데이터 분석을 혁신하세요:지능형 실행 | 코드 생성| 사용자 지정 수식 생성 | 데이터 분석 및 차트 생성| 향상된 함수 호출… |
| 인기 기능:찾기, 강조 또는 중복 표시 | 빈 행 삭제 | 데이터 손실 없이 열 결합 또는 셀 | 공식을 사용하지 않는 반올림... | |
| 슈퍼 VLookup:다중 조건 | 다중 값 | 다중 시트 간 | 퍼지 매치... | |
| 고급 드롭다운 목록:쉬운 드롭다운 목록 | 종속형 드롭다운 목록 | 다중 선택 드롭다운 목록... | |
| 열 관리자:지정된 수의 열 추가 | 열 이동 | 숨겨진 열의 표시 상태 전환 |열 비교하여동일한/다른 셀 선택... | |
| 추천 기능:그리드 포커스 | 디자인 보기 | 향상된 수식 표시줄 | 워크북 및 시트 관리자|자원 라이브러리(자동 텍스트)| 날짜 선택기 | 워크시트 병합 | 암호화/셀 해독 | 목록으로 이메일 보내기 | 슈퍼 필터 | 특수 필터(굵은 글꼴이 있는 셀 필터링/기울임꼴/취소선。。。) 。。。 | |
| 상위 15 도구 모음:12 텍스트도구(텍스트 추가,특정 문자 삭제...)| 50+차트유형(간트 차트...)| 40+ 실용적인수식(생일을 기준으로 나이 계산...)| 19 삽입도구(QR 코드 삽입,경로에서 그림 삽입...)| 12 변환도구(단어로 변환하기,환율 변환...)| 7 병합 및 분할도구(고급 행 병합,Excel 셀 분할...)|。。。 외 더 많은 기능 |
Kutools for Excel 은 300 개 이상의 기능을 제공하며,필요한 기능을 언제나 한 번의 클릭으로 이용할 수 있도록 해줍니다。。。
Office Tab - Microsoft Office(Excel 포함)에서 탭 기반 읽기 및 편집 활성화
- 수십 개의 열린 문서 간 전환에 단 1 초면 충분합니다!
- 매일 수백 번의 마우스 클릭을 줄여주어 마우스 손과 작별하세요。
- 여러 문서를 동시에 보고 편집할 때 생산성을 50% 향상시킵니다。
- Chrome, Edge 및 Firefox 처럼 Office(Excel 포함)에 효율적인 Tabs 을 제공합니다。